



Spark streaming vs Flink
There are ample amount of Distributed stream processing systems available in the market, but among them Apache Spark is being widely used by all organizations, it may be due to the fundamental need for faster data processing and real time streaming data. But with the rise of new contender Apache Flink, one begins to wonder whether they might have to shift to Flink from Spark streaming. Let us understand the pros and cons of both the tools in this article.
From inception Apache Spark (fig: 1.1) has provided a unified engine which backs both batch and stream processing workload, while other systems that either have a processing engine designed only for streaming, or have similar batch and streaming APIs but compile internally to different engines. Spark streaming discreteness the streaming data into micro batches, that means it receives data and in parallel buffer it in spark’s worker nodes. This enables both better load balancing and faster fault recovery. Each batch of data is a Resilient Distributed Dataset (RDD), which is the basic abstraction of a fault-tolerant dataset in Spark.
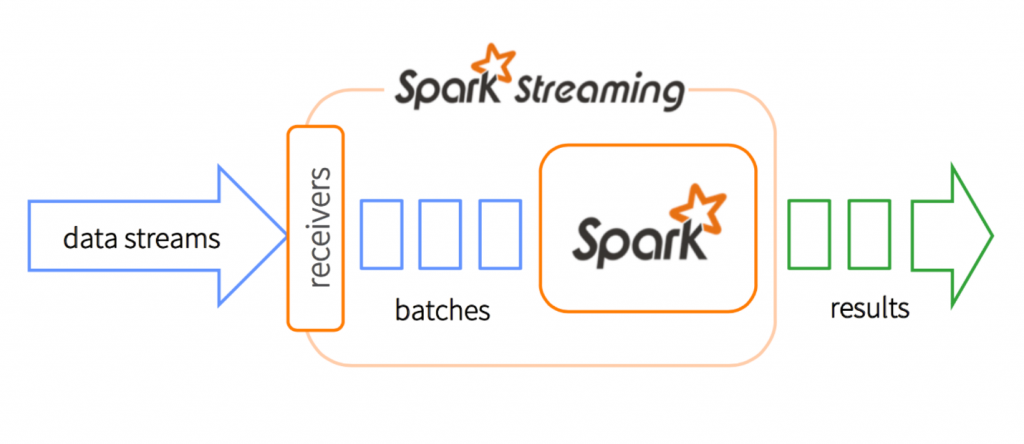
Fig: 1.1
Apache Flink (fig:1.2) is a latest big data processing tool known for processing big data quickly with low data latency and high fault tolerance on distributed systems on a large scale. Its major essence is its ability to process streaming data in real time like storm and is primarily a stream processing framework that can look like a batch processor. It is optimized for cyclic or iterative processes achieved by an optimization of join algorithms, operator chaining and reusing of partitioning.
Fig: 1.2
Both systems are targeted towards building the single platform where you can run batch, streaming, interactive, graph processing, ML etc. While Flink provides event level granularity while Spark Streaming doesn’t provide, since it is a faster batch processing. Due to intrinsic nature of batches, support for windowing is very limited in Spark streaming. Flink rules over Spark streaming with better windowing mechanisms. Flink allows window based on process time, data time, no of records that to be customized. This flexibility makes flink streaming API very powerful compared to spark streaming
While Spark streaming follows a procedural programming system, Flink follows a distributed data flow approach. So, whenever intermediate results are required, broadcast variables are used to distribute the pre-calculated results through to all the worker nodes.
Some of the similarities between Spark Streaming and Flink is exactly-once guarantees (Correct results, also in failure cases), thereby eliminating any duplicates and both provides you with a very high throughput compared to other processing systems like Storm. Also, both provide automatic memory management.
For example, If you need to compute the cumulative sales for a shop with specific time interval then batch processing could do it in ease but rather when an alert is to be created, when a value reaches its threshold level then this situation can be well tackled by stream processing.
Let us now take a deep dive and analyze the features of Spark Streaming ad Flink.
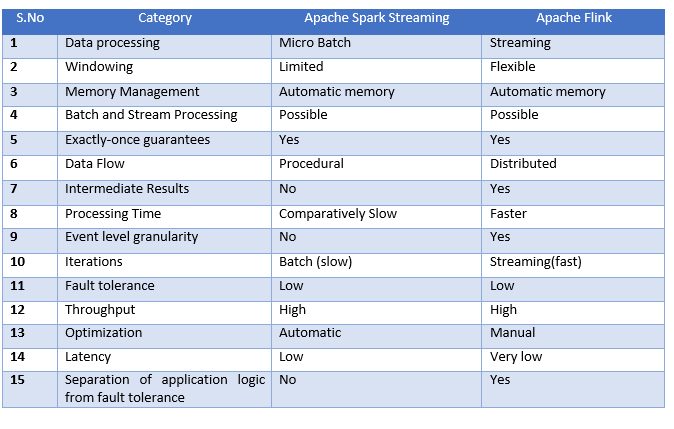
Though Spark has a lot of advantages in batch data processing, but still it has a lot cases to cater in streaming. Flink can process batch processing it cannot be compared with spark in same league. At this point of time Spark is much mature and complete framework compared to Flink. But it appears that Flink is taking big data processing to next level altogether in streaming.
Recent Comments