Online aggregators are websites which bequests in the e-commerce industry by stockpiling the information about various goods and services and conglomerate them from several competing sources, in their websites. The aggregator model assist consumers bestowed, customized, tailored, and cater for the needs and wants of the consumers, later adding value to their feedback and services by revamping their shopping experience.
Who are the Online Aggregators?
They have been graciously welcomed by both the end players- customers and businesses, since it enhances the sale and make a good reach of the product/service to the customers, thus and thus benefits the end players. They have been lustering across many industries like travel, payment gateways, insurance, taxi services, or some firms open up secondary market over internet like letgo, Locanto, vinted and in food ordering services like Campus food, Gimmegrub, Diningin, GetQuick et al.
Business Analytics – As a key factor for the aggregator’s triumph
For bringing in such a dynamic yet strong change in the e-commerce industry, from what has been traditionally followed, what pitch would have had the aggregator firm taken up? What paved as a base for the firm to venture in this space? It is possible by unlocking the marketing data and turn its inside out. This job could be well chipped by business analytics, since it could be portrayed intersection of data science with business.
Business Analytics is the study of data through statistical and operational analysis. It focuses to bring out new insight based on the data collected and utilize them in enhancing the business performance. It is closely related to managerial science, since it is extensively fact-based explanatory and predictive model using statistical analysis to drive management in decision making.
Uber- A study on how Business analytics has augmented their business
In an online aggregator like Uber, this is spread across the world Business analytics plays a crucial role. Uber is an app based technological platform which links the passengers who are up to hire a taxi, to a driver who is ready to assent a ride and Uber takes 20% of the cab fare as its commission and the remaining is pocketed to the driver. The firm has rooted its trial across 444 cities worldwide. In a city like New York it’s whisked around by 14000 thousand Uber cabs while the unorganised hold 13500 taxies. In Los Angles among 22300 cabs 20000 are registered under Uber.
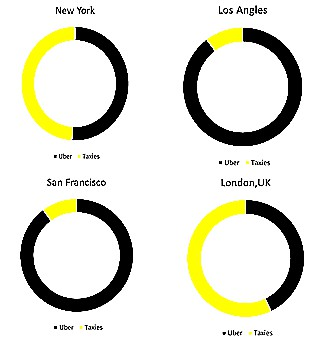
Fig 1: Market share of Uber
Uber maintains a huge data of all its drivers, users and the details of the every city in which it exists so that it can instantly match the passenger with the driver who is nearby. In USA, the traditional taxi meters charge the passengers based on the duration of the rides. But, Uber follows a patent valid algorithm that use the particulars of distance and the duration of the trip. This technique which is used by Uber is called Surge Pricing. A lone feature of this technique is that, the price is multiplied in terms of the surge time, which is when the traffic is overflown, for which the firm had to make a study on the traffic in the New York City (Fig 2). But the passengers are previously warned about the magnifying rate over the normal once. This algorithm advocates the driver to stay back at home due to the shortfall of rides or encourage them to get behind the wheels to gain the extra money while the city is in traffic.
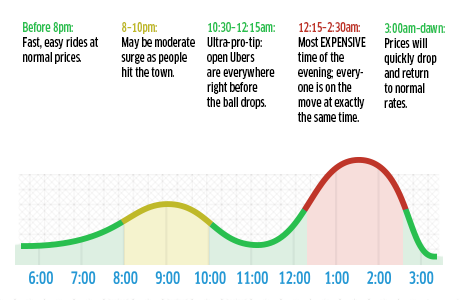
Fig 2: The analysed result of Traffic hours in the New York City and the Surge price that the Uber app informs the passenger about the multiplied charge.
In a study made, Uber inferred that in New York passengers are travelling from almost same locality to almost same destination. When surveyed, majority of them agreed to share their cab even if it’s a stranger. Uber Pool is a service provided by Uber, where a passenger could track another passenger who is waiting to aboard, on the way to be picked up and have to reach almost the same destination. This lets a passenger share the cab with a stranger and cuts down the cost.
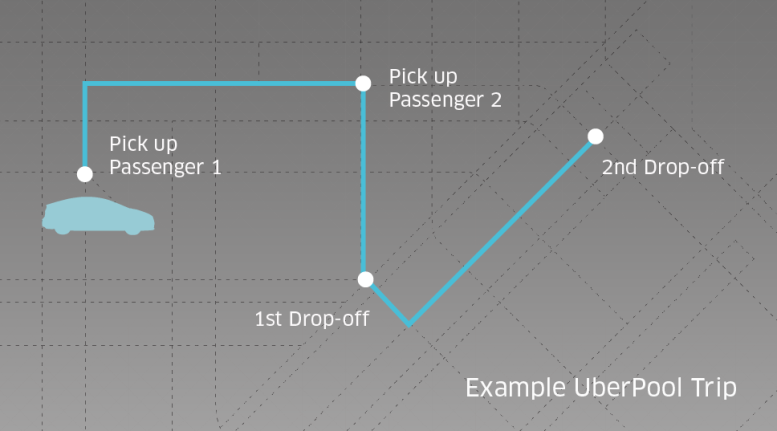
Fig 3: Operation of Uber pool
Uber lets the passenger rate about the driver by the end of every trip based on this knowledge about the city roads, professionalism, driving ability, car quality and punctuality. This is to evaluate the driver and educate them with the skills or even at an extent to rusticate them from the service.
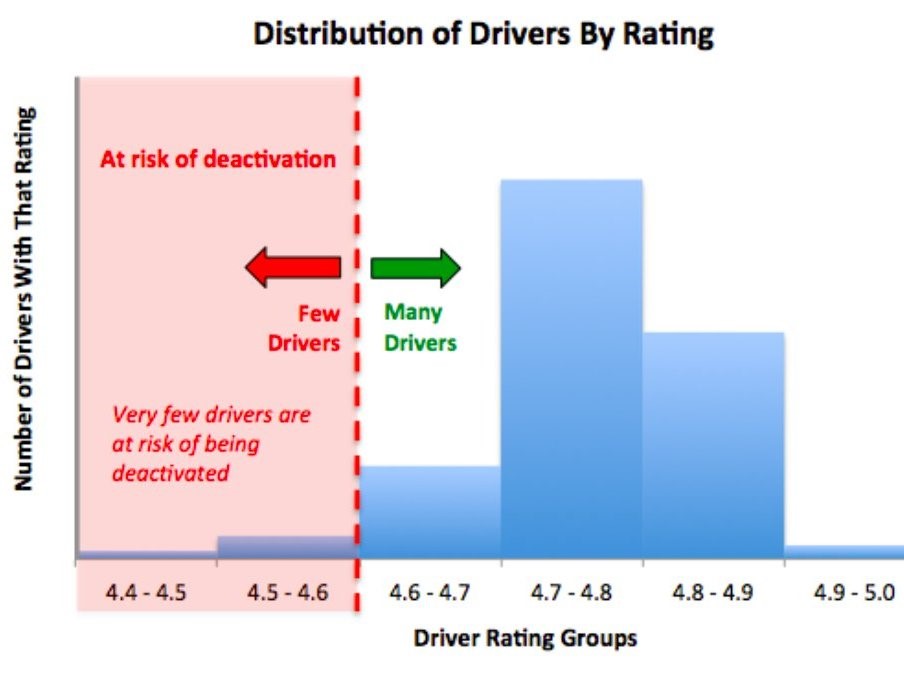
Fig 4: Distribution of drivers by rating and self-assessment chart to the drivers from Uber app.
Conclusion
In the case of Uber’s journey on being an online aggregator, the business analytics have come in handy to evaluate them among the market players, to know about their customer needs and driver’s attitude, to come up with a new strategy like Uber pool letting the passengers to share the taxi and its fare, Rating system to make managerial decision in favour of or against the taxi drivers, to come up with a contemporary pricing method – surge pricing, which charges the passengers based on the changes in demand.
A firm is bound to realize business analytics while making over any managerial decisions, when making a strategic move, when casting a new product or services because this unloads the assumptions and gives in a firm and statistical data in various business obligations. It helps a management make the decision faster and improves the critical performance with the precise data in hand. Business analytics is committed and aids to procure, sustain and reduce the churn rate of any business entity. The analysis subsidize more insights about the market and find the target customers, evaluate the impact created over them due to the changes made in price/ service over the product and realize their expectations. So, Business analytics would be the brain of an organisation to take proactive decisions and plan the business for maximum success by looking into the future.
Reference:
(The data and information used in this article are utilized from the referred sites and documents, and are not self-generated.)
https://www.linkedin.com/pulse/amazing-ways-uber-using-big-data-analytics-bernard-marr
https://georgianpartners.com/data-science-disruptors-uber-uses-applied-analytics-competitive-advantage/
http://www.economicpolicyjournal.com/2015/08/how-big-is-uber.html
http://simplified-analytics.blogspot.in/2011/04/why-business-analytics-is-important-for.html
http://www.computerweekly.com/feature/Business-analytics-make-for-smarter-decisions




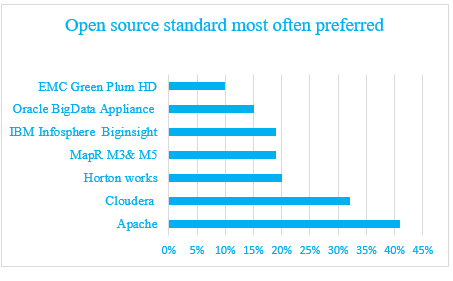
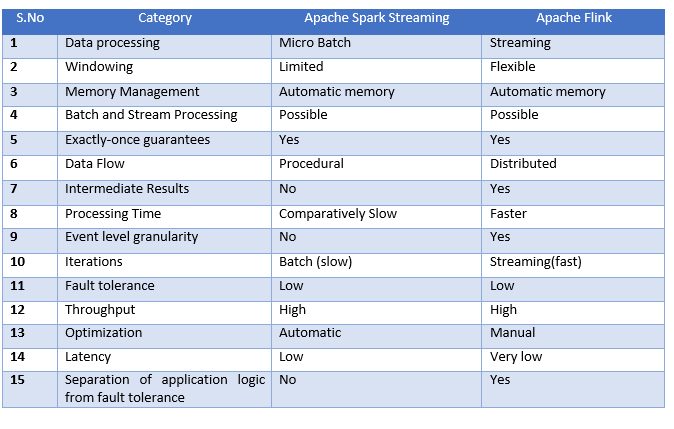
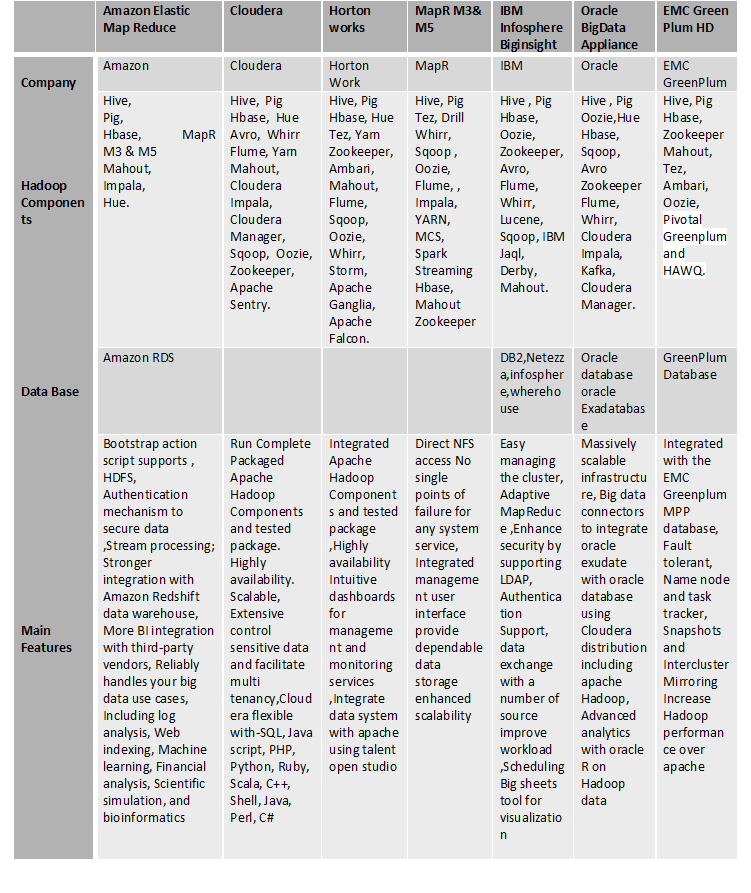 Comparison of latest hadoop distributions
Comparison of latest hadoop distributions



Recent Comments