



Comprehensive Study of Hadoop Distributions
Anyone who is getting attention about big data probably will be aware of how hot Hadoop is right now. Hadoop is powerful open source software framework that makes it possible to process large data sets, doing so across clusters of computers. This design makes it easy to quickly scale-up from a single server to thousands. With data sets distributed across commodity servers, companies can run it fairly economical and without the need of high-end hardware. The number of vendors has developed their own distributions, adding new functionality or improving the code base. Vendor distributions are designed to overcome issues with the open source edition and provide additional value to customers, with a focus on things such as:
- Reliability -The vendors react faster when bugs are detected. They promptly deliver fixes and patches, which makes their solutions more stable.
- Support- A variety of companies provides technical assistance, which makes it possible to adopt the platforms for mission-critical and enterprise-grade tasks.
- Advanced System management and Data management tools –Using other tools and feature like security, management, workflow, provisioning and coordination.
Several infrastructure vendors like Oracle, IBM, Cloudera,Hortonwork,EMC green Plump and other companies also provide their own distributions and do their best to promote their distributions by bundling Hadoop distribution with custom developed systems referred to as ‘engineered systems’. The engineered systems with bundled Hadoop distributions form the “engineered big data systems”.
There are some major players in the industry those are MapReduce, Cloudera, Hortonworks, MapR, IBM, Oracle, and EMC Green Plum.
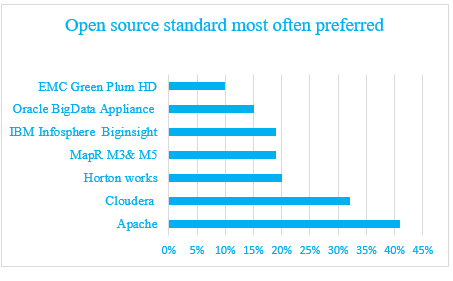
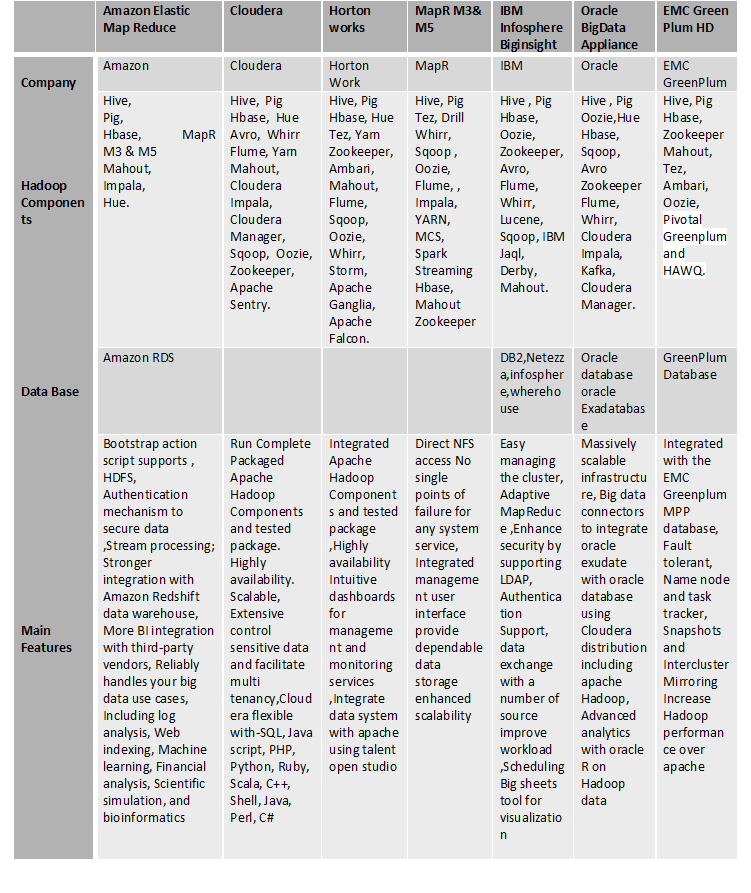 Comparison of latest hadoop distributions
Comparison of latest hadoop distributions
- Amazon Web Services led the pack due to its proven, feature-rich Elastic MapReduce subscription service.
- IBM and EMC Greenplum (now Pivotal) offer Hadoop solutions within strong enterprise data warehouse (EDW) portfolios
- MapR is best if you are looking complete Hadoop stack with all feature.
- Cloudera include component such user interface, security, integration, and make administration of your enterprise data hub simple and straight forward. By using Cloudera manager you can centrally operate big data.
- Hortonworks is the only vendor who offers all Hadoop open source services.
References:
- Hadoop Distributions: Evaluating Cloudera, Hortonworks, and MapR in Micro-benchmarks and Real-world Applications by Vladimir Starostenkov, Senior R&D Developer, Kirill Grigorchuk, and Head of R&D Department.
- EMC federation BigData solution 2015.
- Using IBM InfoSphere BigInsights to accelerate big data time to value (IBM White Paper).
- http://www.wipro.com/documents/Hadoop-vendor-distributions.pdf
- http://www.oracle.com/technetwork/database/bigdata-appliance/overview/bigdataappliance-datasheet-1883358.pdf
- https://www.ibm.com/support/knowledgecenter/SSPT3X_2.1.2/com.ibm.swg.im.infosphere.biginsights.admin.doc/doc/c0057891.html
- https://aws.amazon.com/elasticmapreduce/
Recent Comments